| Accueil - Fonctionnement - Mandrake/Mandriva : 9.2 • 10.1 - - Réseau - Développement - Liens - Forum Présentation - Internet - Bureautique - Utilitaire - Multimédia |
|
|
HTTrack 3.30 et KHTTrack 0.10 sous Mandrake 9.2
|
|
Il arrive qu'on ait besoin de copier
un site internet afin de pouvoir le consulter hors ligne notamment ceux
qui ont une connexion internet par modem classique. Ou encore parce qu'il
y a des nombreuses informations/images que vous souhaitez conserver mais
vous n'avez pas envie de vous amusez à sauver chaque pages/images. C'est pour ces cas que les aspirateurs de site web ont été créés. Sous linux le plus connu se nomme HTTrack |
HTTrack est en programme en ligne de
commande, donc pas très pratique. Heureusement il existe une interface
graphique développée pour KDE qui se nomme tout simplement KHTTrack. Ces
programmes ont été développés principalement par deux français : Xavier
Roche et Stéphane Chapeau. A noter toutefois qu'une interface web est livrée
avec HTTrack et se nomme WebHTTrack
mais je ne l'ai pas encore testée (ça va venir).
Pour commencer il va falloir télécharger
trois fichiers sur différents sites parce que j'ai eu beaucoup de mal à les
trouver car il y avait de nombreux liens qui ne fonctionnaient plus. Si les
liens que je vous donne ne fonctionnent plus ou qu'il y a des versions plus
récentes, faites une recherche sur rpmfind
ou rpm.pbone.net en indiquant
juste le nom du fichier : par exemple "libhttrack". En dernier recours
utilisez google.com avec le
nom du fichier (sans sa version)+ rpm par exemple "khttrack rpm" :
dans les résultats vous trouverez des liens vers les fichiers rpm.
- libhttrack1-3.30-1mdk.i586.rpm : c'est la librairie contenant les fonctions pour le programme HTTrack
- httrack-3.30-1mdk.i586.rpm : le programme HTTrack avec son interface web WebHTTrack
- khttrack-0.10-2mdk.i586.rpm : l'interface KDE pour HTTrack
J'ai téléchargé ces fichiers dans "/home/manyp/httrack/".
On installe toujours les librairies en premier donc on fait un clic droit sur
libhttrack1-3.30-1mdk.i586.rpm => Gurpmi. Ensuite il faut faire pareil pour
httrack-3.30-1mdk.i586.rpm et en dernier khttrack-0.10-2mdk.i586.rpm car il a
besoin que httrack-3.30-1mdk.i586.rpm soit déjà installé puisque c'est juste
une interface graphique.
Passons à la configuration et l'utilisation :
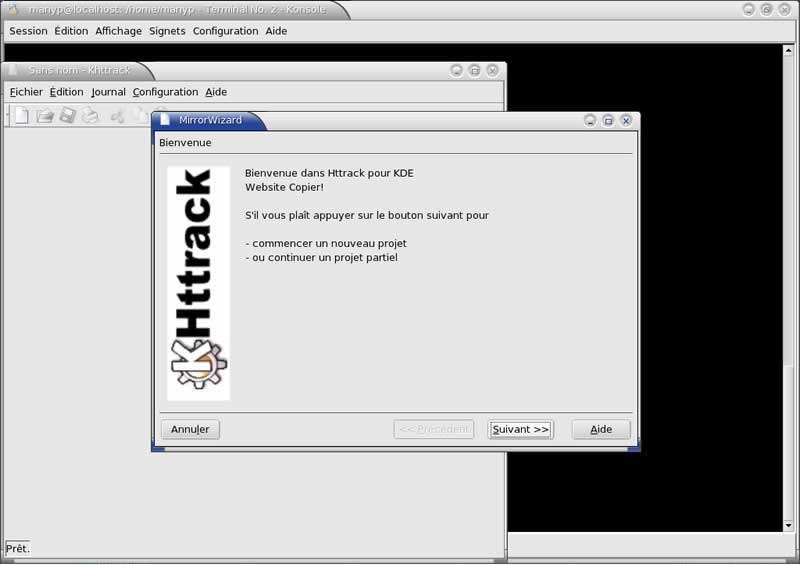 On ouvre Konsole et on tape "khttrack" => le programme se lance |
 On donne le nom du projet (ici test), une description et le répertoire général où seront stocker les différents sites aspirés (ici "~/websites/"). Le tilde (~) indique le répertoire courant, c'est à dire celui où a été lancé la commande khttrack ("/home/manyp/" dans mon cas) |
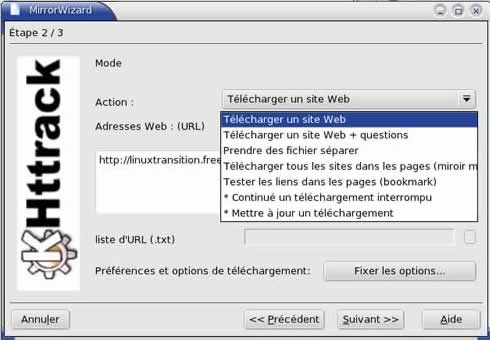 On indique l'adresse du site à aspirer (ici http://linuxtransition.free.fr). On peut choisir différentes actions. Dans cet exemple j'ai pris "Télécharger un site Web" ce qui va aspirer tout le site. |
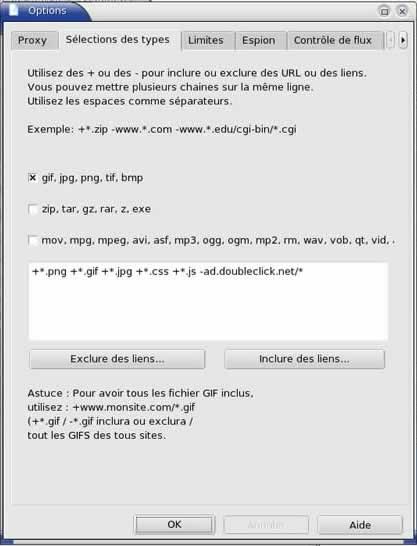 On peut également régler de nombreuses options. J'ai laissé les choix par défaut, j'ai juste coché la case pour aspirer les différents types d'images. |
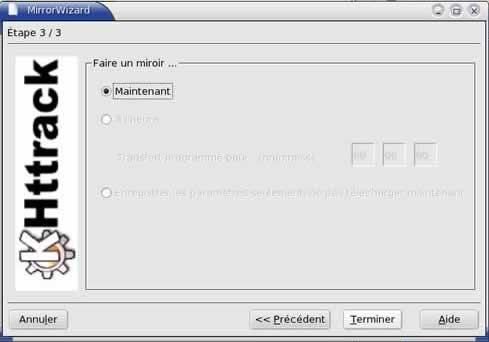 C'est finit pour la configuration. On ne peux pas programmer une aspiration, donc on choisit Maintenant |
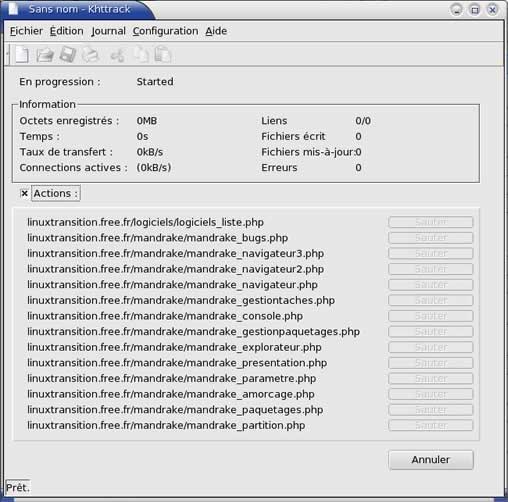 Le processus est lancé, on peut voir les différents fichiers qui sont en train d'être téléchargés |
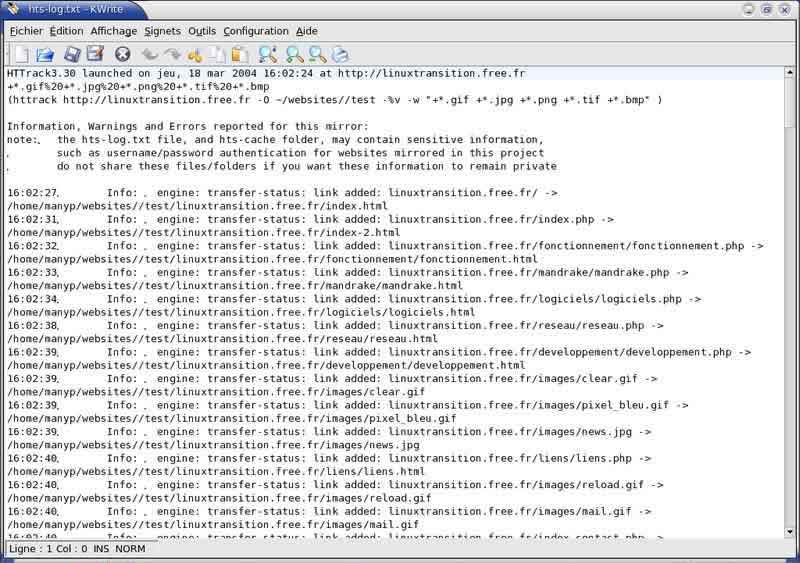 A la fin de l'aspiration, le programme ouvre le fichier hts-log.txt qui décrit tout ce que le programme a fait |
 On remarque qu'un dossier websites a été créé dans "/home/manyp/" avec un sous dossier portant le nom de notre projet (test). A l'intérieur ce trouve le ou les sites aspirés (ici juste "linuxtransition.free.fr") |
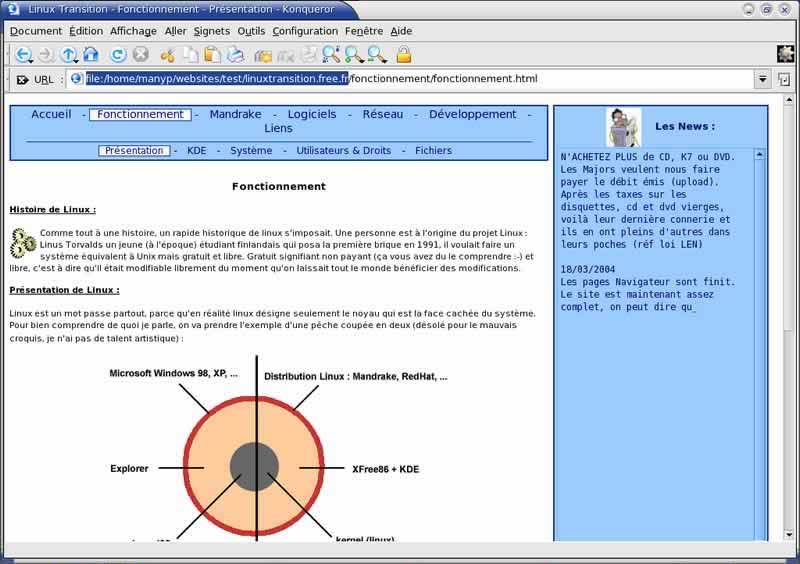 On va dans le dossier "linuxtransition.free.fr" et on ouvre le fichier index.html => on a la copie de notre site. |
Voilà une partie des possibilités du couple HTTrack/KHTTrack. KHTTrack n'étant qu'à la version 0.10 il y a de nombreuses fonctions qui ne sont pas accessibles mais pour une utilisation de base, cela suffit amplement.
Dernière modification de la page : 16/11/2004